My first success at GitHub
In my inaugural month at GitHub, I vividly recall the exhilarating rush of navigating my first PR and deployment train, coupled with the unwavering support and camaraderie of fellow Hubbers.
One of the foremost tasks in the realm of SEO was unraveling the intricate web of what lay visible to the discerning eyes of search engines upon examination of the GitHub website. Enhancing GitHub’s presence on search results pages remained a daunting challenge without a clear understanding of the engine’s perspective. Enter the robots.txt file, a veritable cornerstone known as the robots exclusion protocol or standard. Crafted meticulously, this text file is the guiding beacon for web robots, particularly search engine crawlers. Its directives delineate which pages are open for exploration and which are to remain veiled from prying digital eyes. For seasoned SEOs, the journey of deciphering the engine’s gaze often commenced with a thorough examination of the robots.txt file, unraveling its secrets to discern what lay within the engine’s purview.
In February 2020, I stumbled upon an intriguing revelation during an investigation into GitHub’s performance: the robots.txt file boasted a distinctive configuration. It delineated specified user agents and their allowed criteria, juxtaposed with a catalog of disallowed elements. However, the effectiveness of this setup was marred by the unconventional manner in which directories were blocked. For instance, phrases like “Disallow: /*/*/blob/* ” and “/*/*/wiki/*/*” were employed, proving somewhat ineffective. Additionally, a handful of lines appeared antiquated, failing to align with the evolving dynamics of the business since its inception.
Furthermore, at the very bottom of the robots.txt were the following lines:

The initial line established the criteria applicable to all bots, while the subsequent directive permitted access to a singular file (redirected to /about). The third line unequivocally prohibited the crawling and indexing of all pages. Preceding these instructions, tailored allowances were granted to specific user agents for indexing. The approach entailed restricting most search engine bots, with only a few permitted, and selectively blocking certain directories and pages. This strategic maneuvering had the potential to impede the influx of traffic from search engines to GitHub.com.
Very little existing documentation explained why the robots.txt file was constructed this way. It took some digging to discover this article, which linked to a blog post from May 2016. When I did some digging and spoke with Ben Balter, he mentioned that Lee Reilly had previously worked on the last update for the robots.txt for GitHub.
Around that time, conversations came up in the China Slack channel, called out some issues with Baidu in which one person mentioned:

Conversations circulated regarding GitHub’s sudden disappearance from Baidu’s search results, sparking a flurry of speculation among the team. Theories ranged from a potential abuse report to technical glitches, leaving us grasping for answers. A pertinent question arose amid the discussions: Had anyone delved into Baidu’s diagnostic tools to shed light on the situation?
As the conversation unfolded, I realized that Baidu’s user agent wasn’t among the privileged few listed in the “allowed” section of our robots.txt file. This revelation suggested that Baidu’s access to our pages had been inadvertently restricted.
Despite knowing that a robots.txt directive isn’t foolproof in deterring crawls, Baidu’s exclusion begged further investigation. Could there be underlying reasons beyond our control for their absence in our search results? This lingering uncertainty prompted a thorough examination.
After consultations with the Data Center team at GitHub, it was confirmed that our infrastructure could withstand any potential throttling resulting from modifications to the robots.txt file. With the green light secured, we embarked on the task of scrutinizing each line in the file. Conversations buzzed between the Data Center team, Site Engineering, and other stakeholders, aiming to decipher the rationale behind each blockage.
A GitHub Issue was created to document and track progress. In the future, it would serve as a repository for insights, discussions, and resolutions.
The Issue included:
- A crawl delay to, hopefully, help with the throttling (which my team had tried at Groupon for Bing).
- Updated each line with the star (wildcard) to ensure they would be blocked (they were not effectively blocked before).
- Moved the user profile directories to the bottom for organizational reasons.
- I Added the /account-login line (Google was showing this user account in the site links results for a “github” search)
- I added the /explodingstuff/ directory, which is called out in the Google security warnings for malicious downloads (though it met GitHub’s terms of service as an account including malware to test against).
I chose some successful KPIs based on current traffic from Google and other search engines, which aligned with the overall search market share:
Based on Search Engine Market Share in 2020: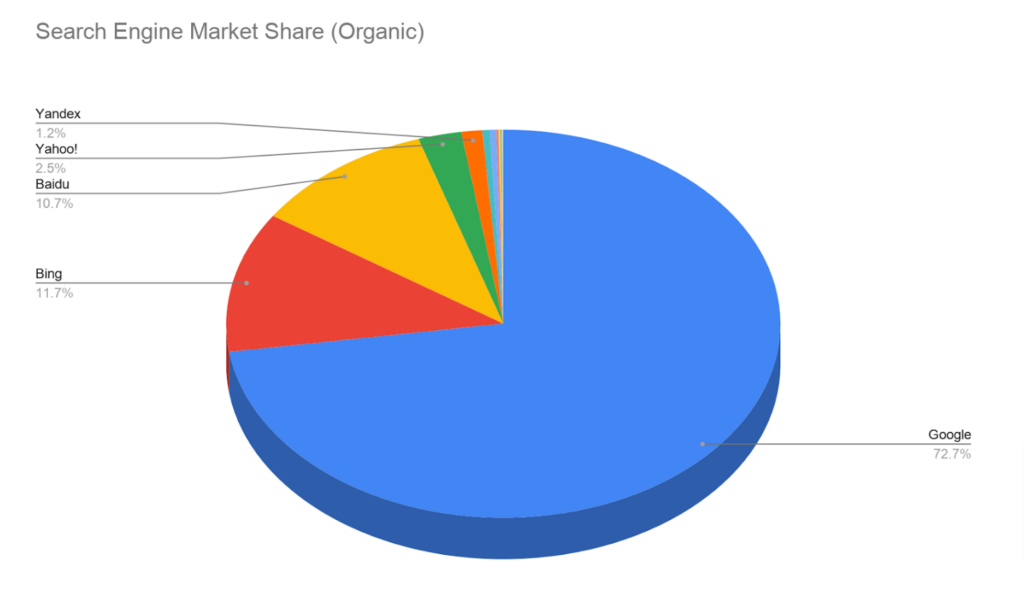
- Baidu was at 10.7% of the search market share for the previous year
- AOL was 3% of the market share
- Google Media (2%) and Bing/MSN Media (1%) add up to 3% of the share (according to PEW research)
I estimated that the lift from the robots.txt file change would be 1.7 M users/visits per month, originating primarily from the Greater China Region.
On May 3, 2020, a Hubber added to the #china thread that GitHub was added back to Baidu search results, saying:
I wanted to update you that we learned from Baidu that the reason we were delisted was, like you suspected, that we blocked their crawlers.
Adding later:
they now manually relisted us but said that if we don’t make changes we will drop again.
Setting up GitHub on my machine proved time-consuming, spanning a week of meticulous configuration. From installing Atom to fine-tuning the Python script responsible for driving the robots.txt directives, each step demanded attention to detail and perseverance.
Finally, after countless hours of tinkering and refining, I mustered the courage to create a Pull Request, eagerly awaiting the scrutiny of one of GitHub’s esteemed Engineers. Their approval would mark the culmination of my efforts and signify the beginning of a new chapter in our SEO strategy.
With eager anticipation, the robots.txt modifications were pushed live on May 13, 2020. The deployment train chugged forward under the guidance of one of the engineers, ensuring a seamless transition from development to production.
The impact of these changes rippled through our digital landscape, eliciting positive responses from Baidu and other search engines. The once elusive presence on search results pages began solidifying, promising increased visibility and traffic.
The Result

- 261% increase in total users from Baidu in China
- 335% increase in signups from Baidu in China
- 503% increase in Baidu signups from marketing pages in China
Total improvements robots.txt changes on May 13, 2020 and the few weeks following:

Comparing the day the robots.txt was pushed live and the two weeks following vs the previous:
- 11 additional search engines with a total of 31% lift in users
- Marketing pages users up by 2.29% (all search engines)
- Signups from marketing pages up 4.66% (all search engines)
The impact of the robots.txt edits surpassed expectations, manifesting in a tangible surge of 1.2 million additional users per month, which was pretty close to the projected estimate of 1.7 million. The success story unfolded against camaraderie and mutual support, with questions being raised and answered with unfaltering enthusiasm. The community’s welcoming atmosphere and accommodating nature fostered an environment where assistance was readily available to all, regardless of expertise or tenure.
This collective effort and willingness to guide and nurture me in my first few weeks as a fledgling Hubber underpinned the remarkable strides made in SEO.
Related Posts








The Story of the SavetheBreakfastSandwich.com Website
The Starbucks Breakfast Sandwich In January of 2008, I was gainfully employed with one of the many technology corporations based in Redmond, WA (No it wasn't Microsoft). It was Concur Technologies, [...]

SEO Checklist – Focusing on Social Media
As some of you know I teach a beginner to advanced SEO Workshop. One of the most asked for items in my talk is the SEO Checklist I have developed just [...]

{kind=link}
{kind=link}
Building a Social Media Community
The staff at Jenn Mathews Consulting use a system for social media marketing called the A.L.I.V.E. system. A majority of our clients have created their Facebook page and Twitter account, but [...]